Measured precision and recall
Every quantitative claim about the verifier on this page is tied to a specific validation run. The fixture is hand-curated, immutable, and published below as evidence. The results JSON files are timestamped receipts - you can inspect them, re-run the harness, and check our numbers against your own.
Latest blind holdout (n = 1,395) - the headline measurement
The current primary evidence is a blind holdout of 1,395 freshly-drawn citations- 1,185 correctly-cited (“clean”) and 210 fabricated or wrong - spanning all eight identifier types, roughly 4x the size of the earlier 350-entry holdout below. Drawn on 2026-06-05 from a recorded seed, constructed title-independently, human spot-checked (105 of 105 sampled entries confirmed fair), sealed, and measured exactly once. A machine check confirms zero overlap (0 of 855 prior entries) with any set the verifier was previously tuned or measured against. We additionally re-measured the sealed set a second time (99.9% verdict stability, zero real changes - the pipeline is deterministic) and ran the opt-in LLM screen over it.
Did it catch the fabrications? On the dominant fabrication patterns - real-DOI + fabricated title, wrong author, wrong DOI, PMID/DOI split, and fully invented - 150 / 150 = 100% (Wilson 95% CI lower bound ~97.6%), each subtype 30 / 30. We also added a deliberately harder near-miss class this round; see the limitation below.
Did it wrongly flag a correctly-cited paper? Across the 1,175 clean reference-list citations: confident (high-confidence) false-accusations were 2 = 0.17%; all high-confidence flags were 9 = 0.8%(Wilson 95% CI 0.4-1.4%); including the low-confidence “needs-a-second-look” bucket, 2.7%. The opt-in LLM screen cuts the any-flag rate to 0.94% by rescuing 22 low-confidence cases - with zero cost to genuine-fabrication recall (it left every eligible fabrication flagged). Calibration is sound: ECE 0.026, with high-confidence verdicts 97% correct.
The two confident false-accusations, in full. Neither is a title-logic error. One is author-form handling - a DataCite literalauthor “de Azcarraga, Jose A.” compared against the cited “Azcarraga,” where the title matched exactly. One is an Open Library record that mis-titles a study guide as its parent textbook - a registry data-quality artifact, where the verifier correctly flagged that the cited title did not match the (mis-titled) resolved record. Both remain in the count; we do not adjust sealed numbers.
A measured blind spot: near-miss semantic flips
This round we added a harder attack class: a real paper’s real title with a single load-bearing word flipped to the opposite meaning (“children” → “adults,” “increases” → “decreases”). The verifier caught only 4 / 30 - the other 26 evade as confident matches, because a one-word change barely moves a character-level title similarity. This is a genuine limitation. It is distinct from the documented AI-fabrication pattern (wholesale-invented titles, which we catch 100%) and closer to a subtle citation error; it is also hard for any similarity-based check. The opt-in LLM screen does not address it - these cases never enter its low-confidence gate. Our roadmap fix is a targeted antonym/negation detector (flag when two titles are near-identical except a meaning-flipping token). We report it here rather than omit it: the larger holdout surfaced a weakness the smaller one could not.
Previous blind holdout (n = 350)
The earlier blind holdout - the lineage that got us here, kept in full for transparency - was 350 freshly-drawn citations (308 correctly-cited and 42 fabricated or wrong) spanning all eight identifier types. It was drawn on 2026-05-26 from a recorded random seed, constructed title-independently, human spot-checked (52 of 52 sampled entries confirmed fair), sealed, and then measured exactly once. A machine check confirmed it shared zero entries with any set the verifier was previously tuned or measured against.
Why measure blind. A number you can re-roll until it looks good is not evidence. The holdout is drawn after the code is frozen and measured a single time, so the result is committed before it is seen.
We found our own bugs - here is the loop. An earlier blind run, on a first holdout, measured a 5.3% false-accusation rate (95% CI 3.2-8.7%). Inspecting it showed the cause was not the title logic: it was (a) a bug in our own dataset construction(raw reference-list author strings stored in a mis-formatted way) and (b) two real gaps in the verifier - initials-first author names (“P Giral”) and a missing “Collaborators” group-author marker. We fixed all three (recorded in the changelog, 2026-05-26), then sourced a completely fresh, non-overlapping holdout - the one measured here - and ran it once: the false-accusation rate fell to 1.8% (CI 0.8-4.0%). We publish both runs in full - the first (discovery) holdout and its receipt are in Receipts below. Quietly discarding the first would have been the dishonest move; the discovery → fix → re-measure loop is the point. That loop continued into the n = 1,395 run above: after this 350-entry holdout we fixed three further normalization known-hards (Greek-letter, numeric-HTML-entity, and Latin-extended title handling - changelog, 2026-06-05), then enlarged the holdout roughly 4x and re-drew it completely fresh. The larger sample tightened the intervals (the high-confidence false-accusation upper bound is now 1.4%, under our 3% bar) and surfaced a limitation the smaller set could not - the near-miss blind spot above.
Measured numbers (blind holdout, n = 350, pre-LLM)
Measured against the live production API on 2026-05-26, deterministic pre-LLM verdicts (the opt-in LLM screen was off). Every figure recomputes from the published receipt.
Did it catch the fabrications? Recall 37 / 37 = 100%(Wilson 95% CI 90.6-100%). Every fabricated and wrong-identifier subtype was flagged: real-DOI + fabricated title (16/16), wrong first author (6/6), wrong DOI (4/4), PMID/DOI split (4/4), fully invented (7/7). The interval’s lower bound, 90.6%, is the honest floor at this sample size.
Did it wrongly flag a correctly-cited paper? This false-accusation rate is the error that matters most. Pre-LLM, across the 285 clean reference-list citations that returned a verdict, 5 were flagged - 1.8% (Wilson 95% CI 0.8-4.0%). Every one of the five was low-confidence, and every one fell in a class already documented as hard:
- two translated titles (an English title cited against a French and a German original);
- one title carrying embedded markup in the registry record;
- one subtitle the citation kept but the registry stored separately;
- one likely online-first vs print year gap (title and author matched exactly).
There were no high-confidence false accusationsin this core arm - and that is what the confidence tier is for. Across the run, high-confidence verdicts were 98% correct, medium 100%, and low-confidence only 25%: the errors concentrate exactly where the verdict already says “low confidence,” which is the bucket the opt-in LLM screen is built to re-examine. So 1.8% pre-LLM is a conservative floor.
Two honest caveats. (1) 13 entries - the arXiv arm and one DOI - hit a transient production gateway error (HTTP 502) mid-run and returned no verdict; they are excluded from the counts above and will be re-measured (a slow upstream, not a verifier result). (2) The 4.0% interval upper bound reflects the sample size; the point estimate is 1.8%, and the with-screen rate is expected to be lower still, since the screen targets exactly the low-confidence mismatches above.
By identifier type (directional). Correctly-cited papers returned matched at: DOI 97.5%, PMID 100%, PMCID 100%, ADS bibcode 100%, ISBN 100%, WHO IRIS 9/10. Per-type counts are small (~12 each, by design), so read these as coverage confirmation, not per-type rates.
Validation set (v1, immutable)
Twenty hand-curated entries across five categories:
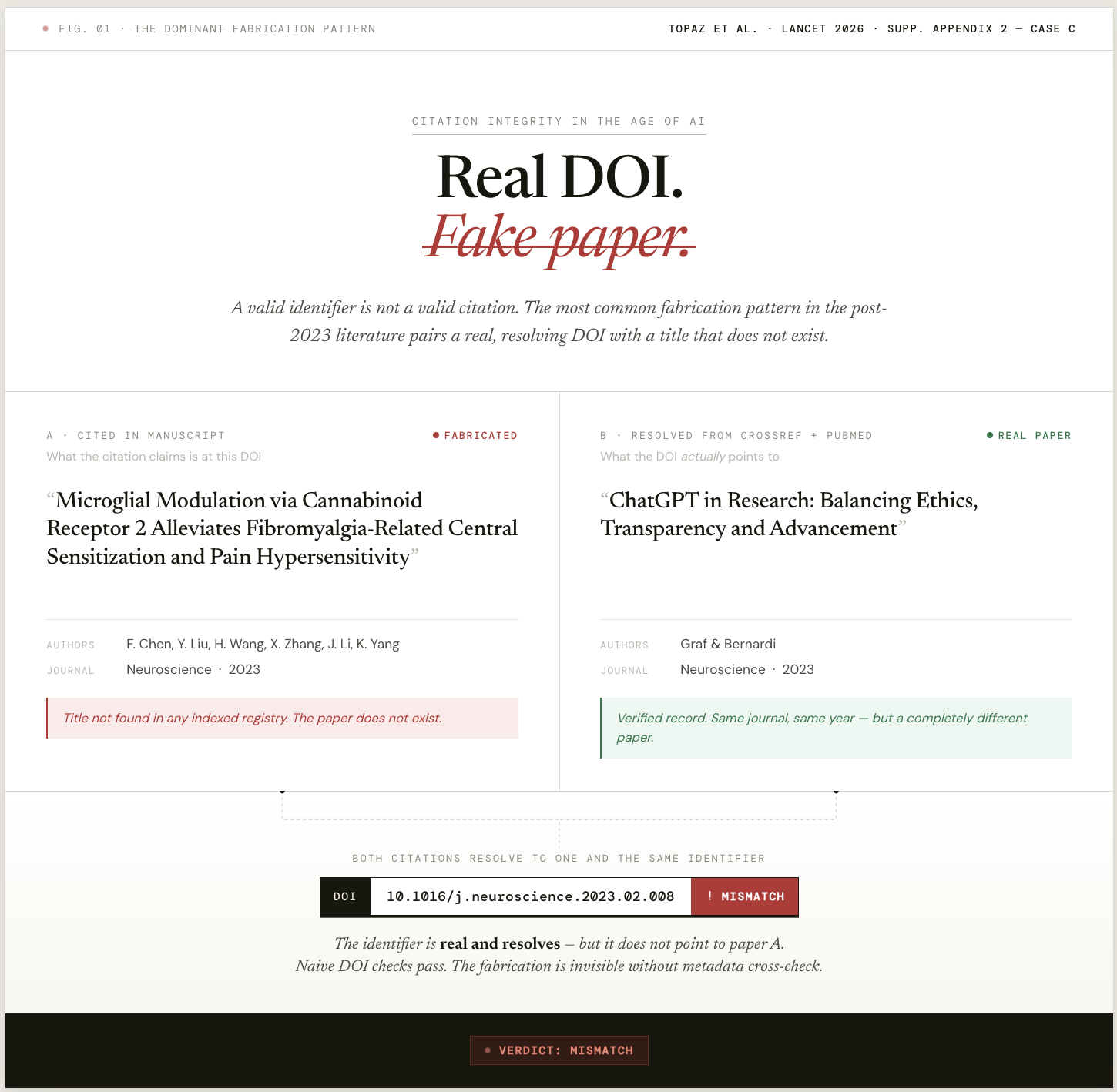
- 3 Lancet illustrative cases.Examples A, B, and C from Topaz et al.’s Supplementary Appendix 2, verbatim. Not our cases - the canonical fabricated-citation examples Topaz et al. chose to publish.
- 5 known-good citations. Real DOI or arXiv ID paired with the canonical title resolved via the scholar-sidekick MCP server. The verifier must return
matched. - 4 wrong-DOI cases (CITADEL “citation error” subtype). Real Paper X’s title paired with real Paper Y’s identifier. Both papers are independently verified; the swap is intentional. The verifier should detect the title mismatch and surface the actual paper as a candidate → verdict
ambiguous. - 4 paraphrase cases. Real DOI + paraphrased title designed to land in the LLM-screen-eligible bucket (mismatch with low confidence). The LLM screen should classify these as
informal_abbreviation and upgrade the verdict to matched. These four entries are the only ones we tuned against the live verifier - they were probed to ensure they exercise the LLM-screen path. The LLM’s verdict on them is what we report. - 4 invented cases. No real paper. Either an invented DOI, an invented title with no identifier, or an impossibly large PMID. The verifier should return
not_found.
Measured numbers (v1 fixture, n = 20)
All figures below are recomputed from the published receipts (downloadable in full below). Each receipt’s per-entry results array carries the verdict, confidence, and resolution source for every case, so the recall, false-accusation rate, and intervals here can be recomputed from the JSON alone - no access to our code required. Confidence intervals are Wilson 95% - wide on purpose, because the fixture is small and every entry is hand-verified.
Verdict conformance.Every one of the 20 entries returned its expected verdict, in both pre-LLM and with-LLM-screen modes. (The receipts’ own metricsblock records this as precision = recall = F1 = 1.000 on the harness’s expected-verdict basis. The figures below recompute ground-truth recall and false-accusation rate, with confidence intervals, so the sample size is visible rather than hidden.)
Did it catch the fabrications? 11 of 11 fabricated and wrong-identifier cases were flagged - recall 100%, 95% CI 74-100%. A perfect 11/11 still only proves recall is at least ~74% at this sample size.
Did it wrongly flag a real, correctly-cited paper? This false-accusation rate is the number that matters most - flagging a genuine citation is the dangerous error. Across the 9 clean citations:
- High-confidence false flags: 0 of 9 in both modes (95% CI 0-30%). The verifier never confidently accused a real citation.
- Including low-confidence flags: 4 of 9 pre-LLM (the paraphrase cases, which the simple verifier routes to the LLM screen by design), falling to 0 of 9 once the LLM screen is enabled.
The gap a plain DOI check leaves. Seven cases pair a real, resolving identifier with a title that does not match the paper it points to - the dominant Topaz pattern:
| Check | Real-DOI fabrications caught |
|---|
| Scholar Sidekick verifier | 7 / 7 (95% CI 65-100%) |
| Plain “does the identifier resolve?” | 0 / 7 |
A resolve-only check catches none of these by construction - the identifiers do resolve, just to the wrong paper. That gap is the entire reason a verifier exists.
Cost and latency. ~0.001 USD per applied LLM screen (4 of 20 entries triggered it); total run under half a cent. Per-request latency p50 ~ 2 s, p95 ~ 10 s (pre-LLM, point-in-time, measured over the network and including one rate-limit retry).
How to read this. A reproducible methodology check on hand-picked adversarial cases, not a 99-percent-style accuracy claim. The intervals are wide because n = 20 - the 1,395-entry blind holdout above is the larger clean arm that tightens the false-accusation-rate bound.
Receipts
Latest run (n = 1,395, 2026-06-05):
Earlier runs (kept in full for transparency - the discovery → fix → re-measure lineage):
The fixtures are marked immutable. Each new measurement gets its own versioned, immutable fixture; old numbers always cite the specific fixture version they came from.
The validation data is released under CC BY 4.0 - reuse it, including for independent replication, with attribution.
Frequently asked questions
Is this catching AI-generated citations specifically, or any fabrication?
Both. The fabrication pattern is the same regardless of origin: a citation pairs a real, resolvable identifier (DOI or PMID) with a title that does not correspond to the paper at that identifier. Topaz et al. note the steep increase since 2023 strongly implicates LLM authorship, but the verifier checks the structural disconnect - claimed title versus resolved title - not who wrote the citation.
Does the verifier work for non-biomedical citations?
Yes. CITADEL (the pipeline Topaz et al. used) covers DOI and PMID - the biomedical identifier surface. The Scholar Sidekick verifier covers DOI, PMID, PMCID, ISBN, arXiv ID, ISSN, NASA ADS bibcode, and WHO IRIS URL - eight identifier types, which extends the same cross-reference methodology into books, computer-science and physics preprints, astrophysics, and institutional grey literature.
Can I run this against an entire manuscript bibliography?
In batches, yes. The web tool at /tools/citation-verifier accepts pasted references or a .bib / .ris / .csl-json upload and verifies up to 10 at a time. The same backend is a REST endpoint at /api/verify and a verifyCitation MCP tool callable from Claude Desktop / Cursor - script either to run a full manuscript bibliography one reference at a time; rate limits scale with plan tier.
What about retraction status?
Retraction is a different signal. A real, correctly-cited paper can still be retracted. Scholar Sidekick exposes retraction-checking at /tools/retraction-checker (Retraction Watch via Crossref). It is not wired into the verifier endpoint yet - that is a separate planned phase. If you need both signals on a bibliography today, call them separately.
What does the verifier cost?
The /api/verify endpoint is free at the anonymous tier with a published rate limit. The LLM screen - used only when the simple verifier returns mismatch with low confidence - is gated to authenticated first-party callers and paid RapidAPI tiers, since each model call carries a real per-call cost that Scholar Sidekick pays to the model provider. We protect against runaway spend with a server-side daily cap; once that cap is hit, subsequent verifier requests fall back gracefully to the non-LLM verdict.
How did you measure precision and recall?
We hand-curated a 20-entry fixture set sourced from the Topaz et al. supplementary appendix and from independent registry lookups via Crossref, PubMed, and arXiv. We ran every entry through the live verifier and counted how many actual fabrications were flagged (recall) and how many legitimate citations stayed clean (precision). Numbers and the full fixture are published below; the JSON is immutable for v1. Twenty entries is a methodology check on hand-picked adversarial cases, not a statistically large benchmark. We have since measured a 1,395-entry blind holdout - drawn after the code was frozen and measured exactly once (plus a repeatability re-run) - which returned 100% recall on the dominant fabrication patterns and a 0.8% high-confidence false-accusation rate (Wilson 95% CI 0.4-1.4%). An earlier 350-entry holdout, and the first run that surfaced our own bugs, are also published below with full receipts - the complete discovery -> fix -> re-measure lineage.
Why is this called complementary to CITADEL?
CITADEL is offline, post-publication, PMC-XML-only, and ran retrospectively across 2.5 million papers. Scholar Sidekick is online, on-demand, available at write or review time, and covers six identifier types CITADEL does not. The two surfaces serve different points in the publication lifecycle: CITADEL audits the literature retrospectively; Scholar Sidekick checks the citation as it is being written or peer-reviewed.